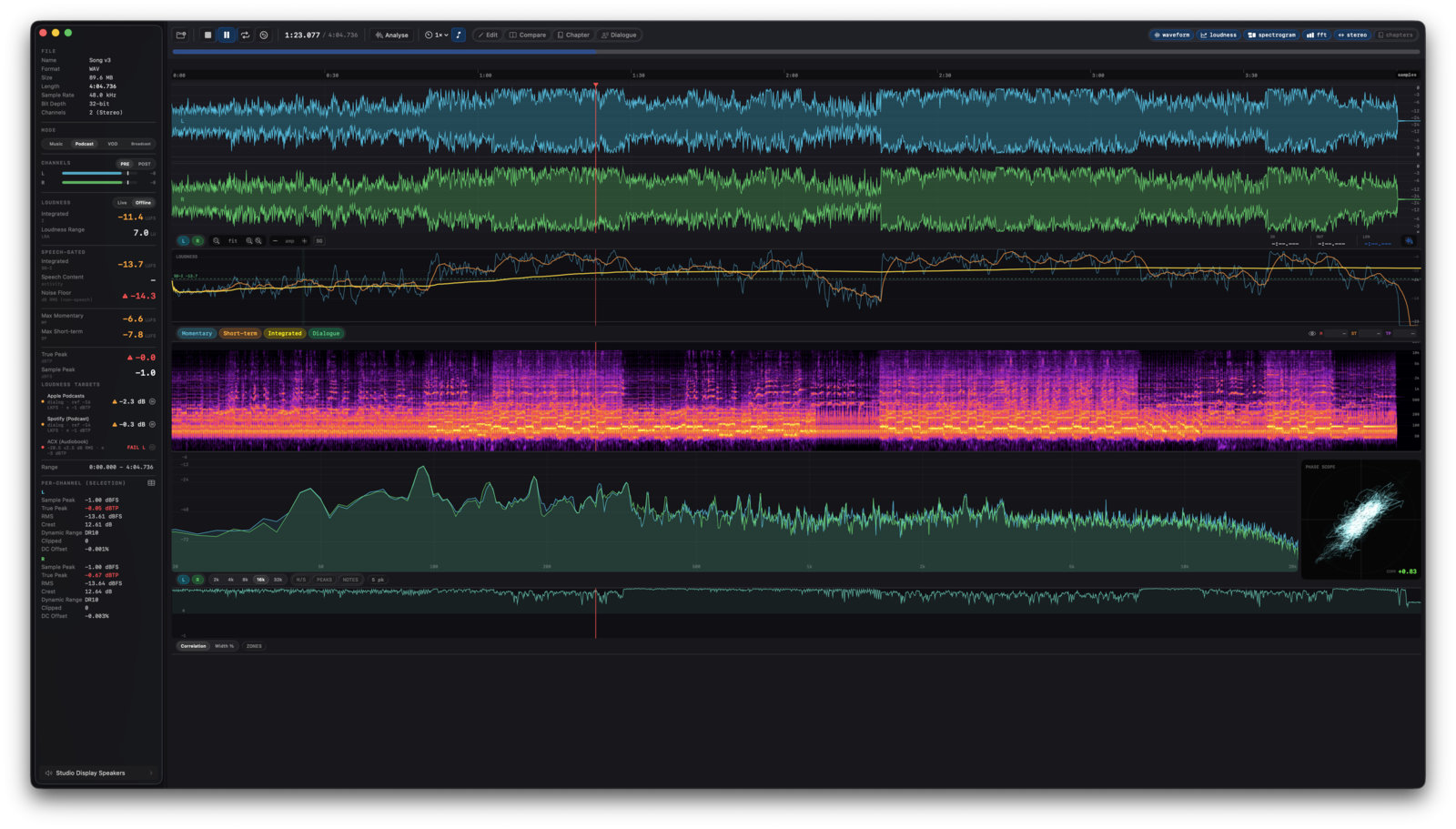
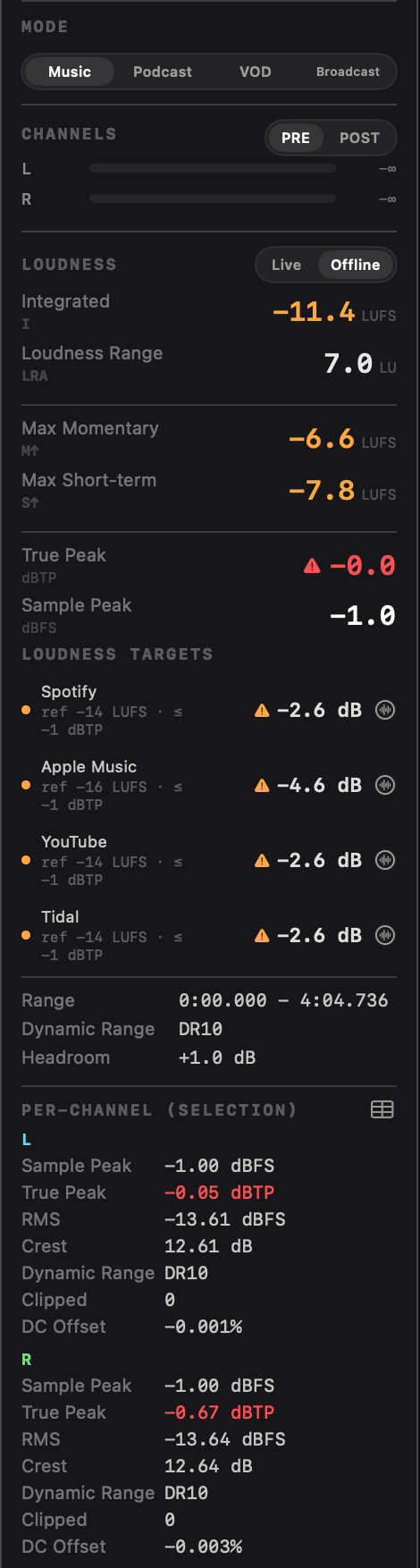
EBU R128 loudness
Full ITU-R BS.1770-4 implementation with K-weighting (cascaded biquad sections), 100 ms gating blocks, dual gating (−70 LUFS absolute, −10 LU relative), 4×-oversampled true peak. Live Momentary / Short-term / Integrated / LRA / True Peak in the sidebar; offline integrated and LRA on any selection. The included test target validates the implementation against the EBU R128 loudness test set (Tech 3341/3342).
Speech-gated LUFS
A neural Silero VAD runs on every loaded file and highlights speech blocks in teal on the waveform. The same speech mask gates a parallel integrated LUFS measurement; Netflix's speech-gated target (−27 LKFS ± 2) becomes a number you can read off the panel. A spectral fallback VAD covers the rare case where Silero is unavailable.
Loudness targets
Four delivery modes and a 22-target catalog. Music reports the gain each platform will apply to your master, and tells the truth about asymmetric platforms (Apple Music, YouTube, Tidal turn loud tracks down but never boost quiet ones, so a quiet master reads "as-is" on those rows). Podcast / Spoken Word mixes streaming penalties with the ACX audiobook spec, including the live −60 dB RMS noise-floor check that's a common reason ACX rejects audiobooks. VOD verifies against the Netflix / Prime / Apple TV+ / Disney+ / Max −27 LKFS dialog-gated band. Broadcast verifies EBU R128, R128 S1 short-form (with Max Short-term ceiling), ATSC A/85 (CALM Act), ARIB TR-B32, and OP-59. Dialog-gated targets read off the speech-gated path so they ignore room tone and music beds. Press a row's match toggle to hear playback at the target's level with a true-peak limiter at the spec ceiling; works for dialog-gated targets too. Integrated and dialog-gated rows also carry a Normalize button that commits to the target: it opens Edit mode pre-filled to that target, stating its Basis (Integrated LUFS or Dialog-gated LKFS) with a Now / Target / Gain readout and the dBTP ceiling as the only editable field, then shifts the whole file by one uniform gain and holds the ceiling with a two-pass true-peak limiter, saving a new file. And when a row's true peak breaches its ceiling, a one-click Limit TP button caps the inter-sample peaks without touching loudness, the same one-click fix as Normalize but for a true-peak overage. Only the ACX RMS target stays compliance-only with no Normalize button, since a gain can't satisfy its noise-floor requirement.
FFT spectrum
Real-time logarithmic spectrum with five window functions (Hann / Hamming / Blackman / Blackman-Harris / Flat Top), each tuned for a different job, from general use to closely-spaced harmonics to calibration-grade amplitude reads. Hover the mouse anywhere on the curve to see the frequency, level, and the closest musical note with cents deviation.
Spectrogram
Rolling time-frequency display with four perceptually-distinct colormaps (Inferno / Turbo / Plasma / Viridis), logarithmic or mel frequency scale, and a configurable dB-range window. Mel scale gives more resolution where dialogue actually lives. Time resolution is configurable too: five FFT overlap settings from 75% (~47 columns/sec at 48 kHz) up to 98.4375% (~750 columns/sec) for ultra-smooth gradients at high zoom. The view follows the same Live / Offline split the loudness section uses, with independent stores so live playback never overwrites your Analyse result. While playback is paused, clicking on the waveform or spectrogram (or pressing arrow keys) recomputes the FFT for that position so the spectrum view matches the column under the playhead.
M/S stereo & phase
A correlation curve (Pearson, −1 to +1) plus a Lissajous phase scope. Optional zone colour mode tints the curve by stereo character: mono, narrow, stereo, wide, out-of-phase, with a plain-English hover label so you can read what the numbers mean.
Compare mode (⌘2)
A toggled mode with its own sky-blue toolbar. Drop in up to six audio files (slots A through F), switch between them on bare 1-6 keys, or drag a file onto the Compare toggle to add it in one gesture. Apply LUFS-based level-matching with one click so the louder version doesn't always win. Polarity-invert any slot. Offset (samples + ms) and gain (dB) readouts are editable TextFields with ↺ reset buttons and right-click reset; type the value you want, hit Return. Hit auto-align and let decimated cross-correlation lock the slot to slot A. Listen to Diff is a per-slot toggle (or bare D) that swaps the active slot's playback for the cached A−X residual through the same waveform / spectrogram / export paths: one-key A/B between source and residual. Export the residual to WAV with ⌃⌘E.
Edit mode (⌘1)
Non-destructive editing without booting up a DAW, with keyboard shortcuts listed in the Edit menu. Trim to selection, Cut a range out of the middle and crossfade-join the sides (⌫), insert silence (at the playhead, or before / after / replace a selection), apply linear gain, invert phase, fade in/out (linear / log / equal-power), normalize to a peak target or to a LUFS target with an automatic 5 ms lookahead true-peak limiter (the ceiling is enforced against the 4× oversampled inter-sample peak, not just the sample magnitude), cap inter-sample peaks at a dBTP ceiling with the standalone Limit TP operation, level spoken word with Level Dialogue (a region-aware gate that ducks the room tone and optionally lifts the voice to a target without the floor riding up), remove DC offset, swap channels, or split the file into N mono WAVs. Normalize and Limit TP respect a time selection, so you can fix one hot section without re-rendering the whole file. 16-level undo/redo. Always saves as a new file.
Chapter mode (⌘3)
Built for audiobooks and long-form podcasts. Detect splits the file at silences (default 2 s under −55 dB) into a chapter ribbon, then Analyse Loudness runs a full pass per chapter: RMS, integrated LUFS, true peak, sample peak, LRA, max momentary, max short-term, speech-gated LUFS, median noise floor, speech %. Every chapter is independently flagged against the three ACX delivery gates (RMS outside [−23, −18] dB, TP > −3 dBTP, NF > −60 dB RMS) and against the book's own median (default ±2 LU on the integrated LUFS). Level chapters (the Level… popover) fixes the consistency flag in one move: bring every chapter to a common loudness, by RMS (the ACX metric, default) or integrated LUFS, to the book median or a fixed value. Drag boundaries on the waveform, click one and hit Remove to merge two chapters, rename slots, export the layout (or the per-chapter metrics as CSV), or import a hand-crafted one. The chapter table lands in the PDF / JSON report with the same red-cell signalling so a producer reads the rejection conditions without opening the app.
Dialogue mode (⌘4)
Hand-correct what the Silero VAD got wrong. Drag regions on the waveform: body to move, edges to resize. Add from selection, mark I / O the DAW way, S to split at the playhead, Delete to remove. 50-step undo / redo including drag operations. Per-region tinting tells you provenance at a glance: green for pristine Silero output, amber for VAD regions you've edited (with a ghost of the original VAD bounds drawn behind), blue for hand-painted regions. Edits auto-save to a versioned .dlg.json sidecar next to the audio file, debounced 500 ms, so re-opening the same file re-applies your edits. Reset to VAD nukes the sidecar and re-runs Silero with the current Settings → Speech tuning (Threshold, Minimum region duration, Merge gap). The corrected regions feed straight into the speech-gated loudness path so dialog-gated LUFS, ACX noise-floor, Netflix / Apple Podcasts compliance, and Chapter mode's per-chapter speech metrics all benefit from the cleanup.
Channel routing
A dedicated Output window (⌥⌘O) holds the device selector and a flexible N → M routing matrix with per-route gain trim and per-route polarity. Switch between Matrix view (patch-bay grid: a silent row or unused source column jumps out at a glance) and List view (typeable dB fields per route). One-click mixdown preset library filtered to the current file and device: stereo basics, 5.1 to Lo/Ro and Lt/Rt (Pro Logic II encoding with surround polarity), 5.1 to Mono, 7.1 to Lo/Ro and Lt/Rt, 7.1 to 5.1. Coefficients follow ITU-R BS.775-3 and the Dolby PLII spec. Save your own routings to a Saved presets library with JSON import / export for sharing setups. Pick whether the loudness measurement reads PRE (the raw file) or POST (after routing and gain) so you can verify surround channel orders, audition a downmix, or measure the resulting stereo pair without modifying the file. When the downmix is right, Render to File… writes it to a new audio file (only the routed outputs are written, so a 5.1 → stereo fold makes a 2-channel file), never over the source.
JSON & PDF reports
Export the full set of measurements with ⇧⌘E (JSON) or ⌥⌘E (PDF). A freshly-loaded file renders the complete metric grid in the PDF without an explicit selection analysis pass: integrated LUFS, 4× oversampled true peak, sample peak, LRA, Max Momentary, Max Short-term, DR, speech-gated LUFS, and per-channel peak / RMS / crest / DC / clipping all populate from the live engine. Pick what's included: loudness curves, stereo width, per-channel stats, violation list. The JSON is a stable schema for archival and CI use; the PDF is the same content rendered for human reading. Each row in loudnessTargets.targets[] carries an inline verdict object (status, actualLUFS, penalty and non-compliance fields) so a downstream script can branch on pass / fail without recomputing.
specula CLI
Four subcommands: analyze, compare, edit, report, built on the same BS.1770 + speech-gated LUFS + stereo-correlation engine the app uses, so batch QC scripts get the exact same numbers. Pretty-printed JSON with sorted keys so diffs across runs stay deterministic. specula report --format json|html|pdf writes the same dark-themed report the app's preview window renders, without opening it. specula compare A B --out-diff residual.wav --match-loudness writes the level-matched A − B residual to a WAV so a script can branch on residual energy without re-loading the file. Ships inside the app bundle: Specula → Install Command-Line Tool… links it into /usr/local/bin.
Shortcuts + Siri
Eight App Intents: Get Measurements, Compare Files, Get Compare Diff, Get Report, each in a file-input and a path-input variant, return chainable structured output so a downstream Shortcut step can compare against Integrated LUFS, True Peak, Loudness Range without parsing JSON. Walk a folder, flag every master above a target threshold, AirDrop the failures: no shell glue. Spotlight phrases ("Measure with Specula", "Build a report with Specula") register all eight intents. Path variants accept quotes, spaces, tildes, and file:// URLs so clipboard-driven workflows just work.
Format support
WAV, AIFF, FLAC, CAF, MP3, AAC, and anything else AVFoundation can decode. Channel layouts from mono and stereo through 3.0, quad, 5.1, 7.1, and arbitrary n-channel. Bit depth and sample rate read directly from the file metadata.