Tier 1 is a Silero neural VAD (MIT-licensed, run via FluidAudio). On load the file is downsampled to 16 kHz mono and classified per 100 ms block. Tier 2 is a spectral fallback that covers the rare case where Silero is unavailable, it classifies on four spectral features (an HF gate, a 300 to 3 400 Hz band-energy ratio, spectral flatness, and a harmonicity-plus-flux test) so the speech-gated path still produces a result.
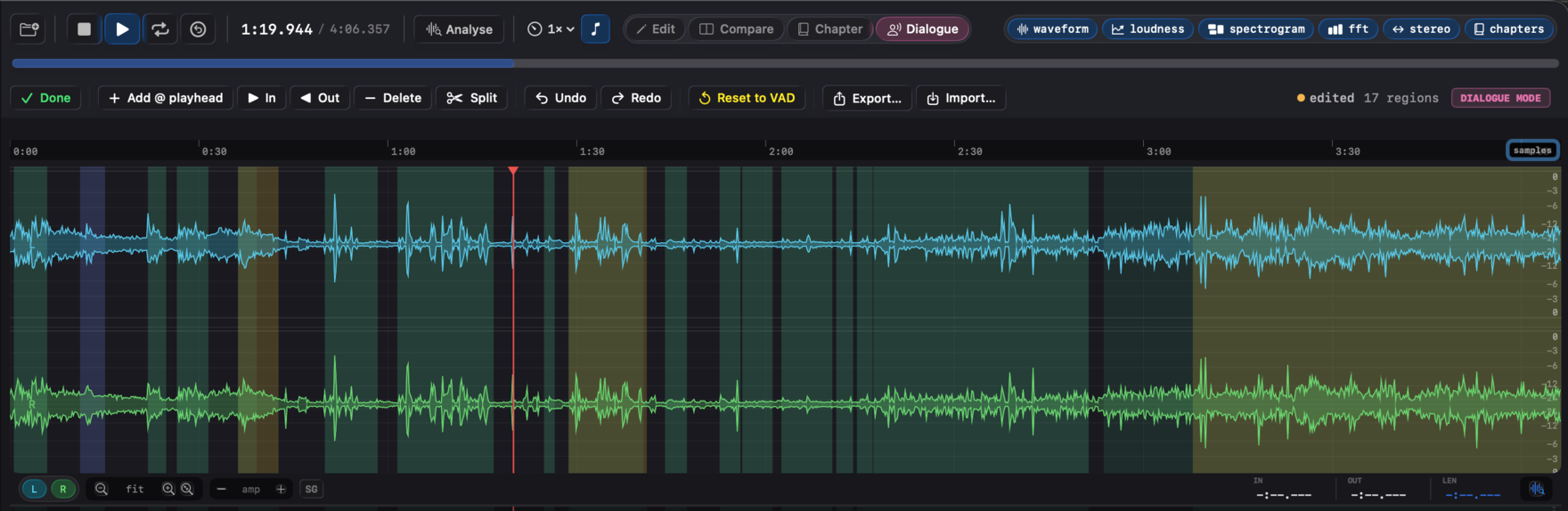
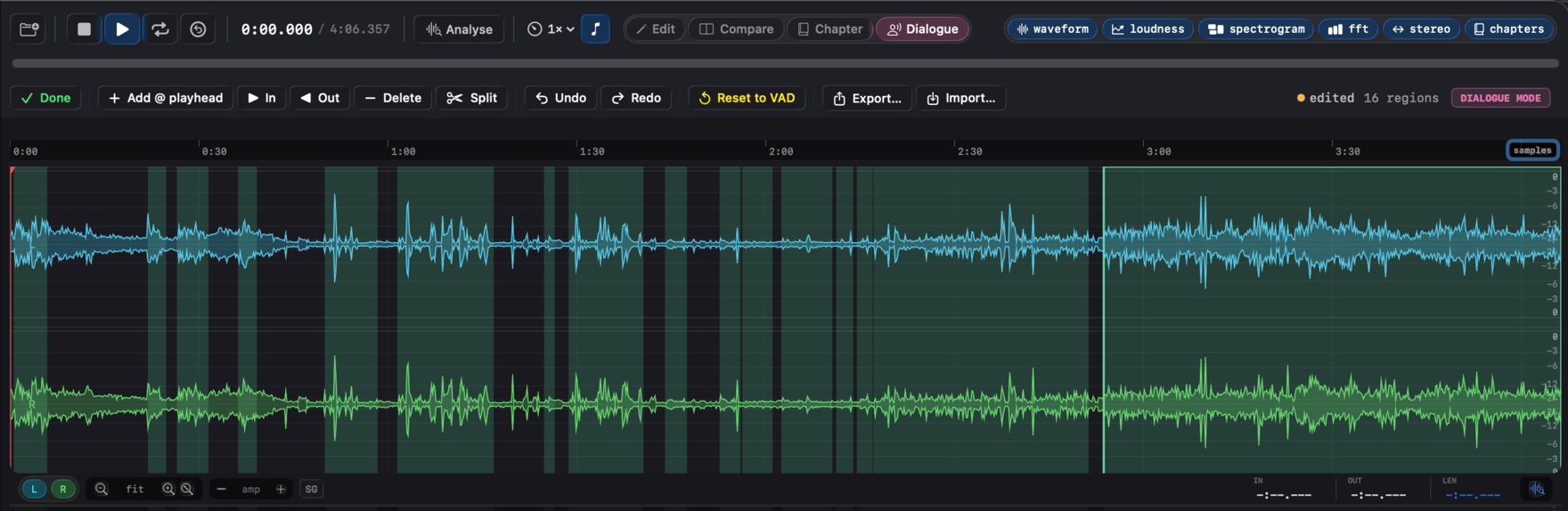
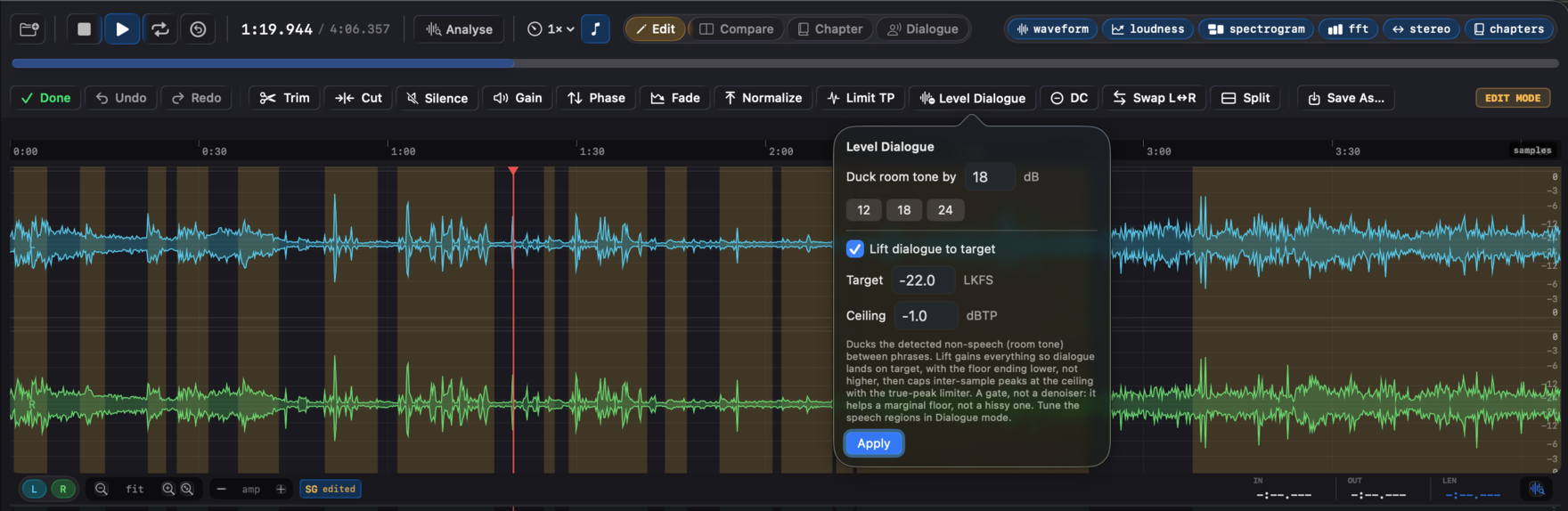
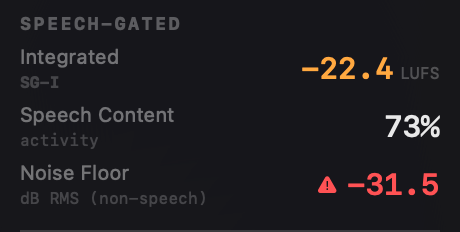
The corrected regions feed straight into the speech-gated path. When you fix regions in Dialogue mode, the dialog-gated LUFS, the noise-floor reading, and the Apple Podcasts / Spotify Podcasts verdicts all recompute against the speech and silence you confirmed, not what the raw VAD guessed. Region tint shows provenance: teal for pristine Silero output, amber for VAD regions you've edited, blue for ones loaded from a sidecar.
Bias the detector to your material in Settings → Speech. Three sliders re-run detection in about half a second: Threshold (0.1 to 0.9, default 0.5, lower picks up quieter speech), Minimum region duration (0.05 to 2.0 s, default 0.10, raise to reject clicks and short interjections), and Merge gap (0.05 to 2.0 s, default 0.10, larger values fuse nearby regions through breath pauses). Reset to VAD discards your edits, deletes the sidecar, and re-runs Silero with the current tuning.